Working with large repositories is a daunting task. While Git works with most repository sizes, its speed is inversely proportionate to the size of the repository. Let’s take the example of the GitLab rails monorepo. Being part of the Gitaly team means that we also make changes to the rails repository from time to time.
The GitLab repository is active with around over 300k commits, 14k branches and 110k merge requests. Let’s look at some ways to squeeze some performance out of git while cloning such repositories. We’ll use this repository as an example to go over the optimizations possible.

Before we jump into it, let’s talk about the different object types available in git. Objects in git follow a graph structure.
- Blob: Blobs in git are objects which contain the data of a file. Blobs do not hold any other information such as path/filename, just the contents of a file.
- Tree: Trees in git refer to the directory and file structure of a repository. Files are trees which hold a filename and point to a blob (contents of the file). While directories are trees which contain other trees (sub-directories or files).
- Commit: Commits in git are a point in time reference to how the repository looks. Each commit points to one or more parent commits and also a tree object.
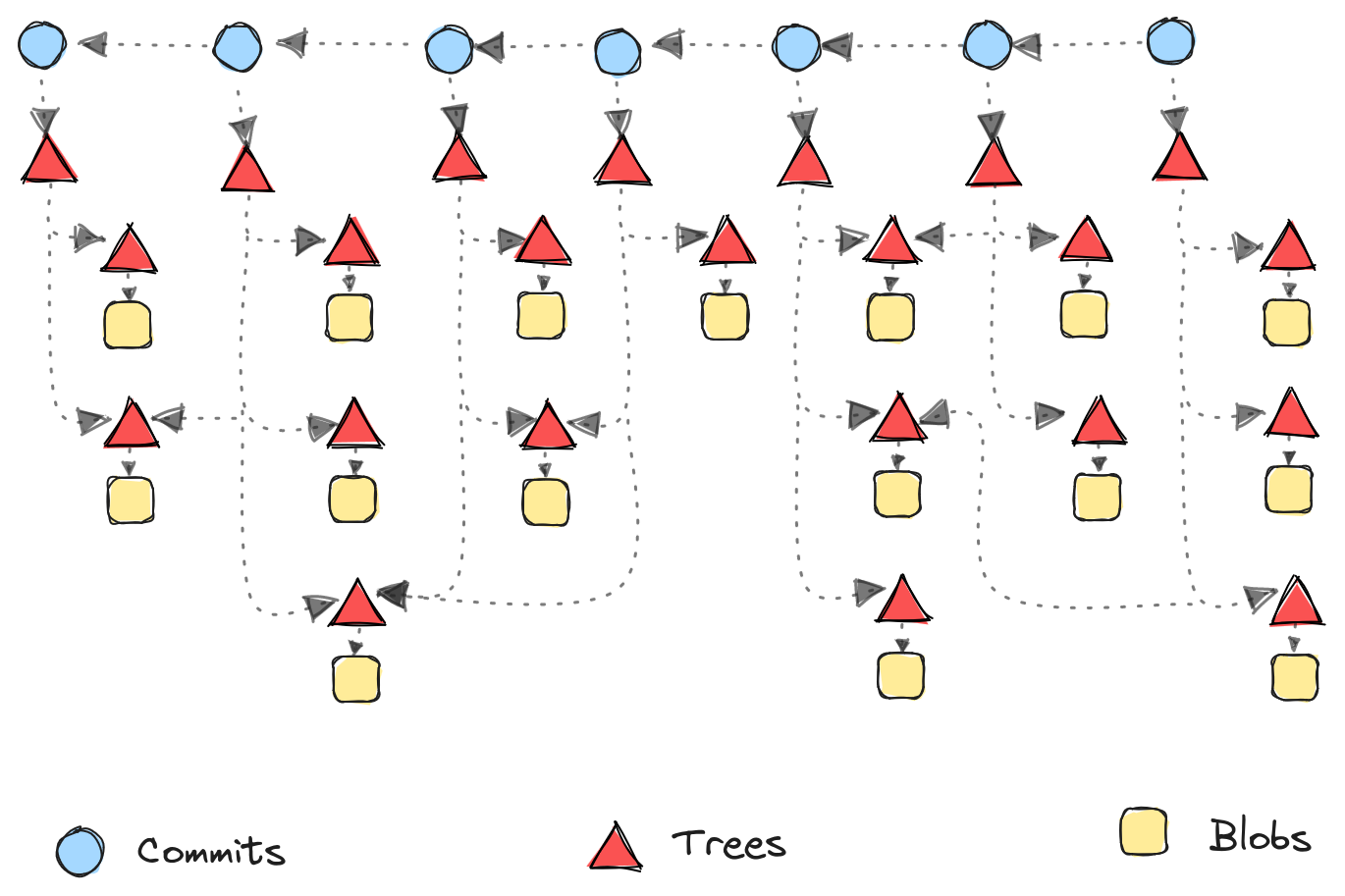
The graph shows a simple repository wherein each commit points to its parent. Each commit also points to a set of trees. Some trees are shared amongst commits. Trees could point to other trees (directories) or blobs (files) recursively.
Cloning the repository Link to heading
Let’s clone the gitlab repository without any optimizations. This will serve as a baseline to compare some of the options we discover later on.
|
|
What’s important to notice here is not only the time taken, but also the number of objects that we had to fetch1. By default, git fetches all commits, trees and blobs.
For benchmarking, we’ll use a naive approach of checking our an older branch using git checkout. Let’s use a branch last updated on March 11, 2022: demo-add-training-url. We can see that in our baseline repository, it takes 6.5s to complete.
|
|
Now we can move onto the more interesting bits, optimization!
Shallow clone Link to heading
When you want to clone the repository and don’t care about its history, we can ask git to only fetch the current state of the repository. We can tell git clone to ignore the history by using the --depth=<N> flag. Here N denotes the number of commits we want to fetch. With this, git only fetches the default branch and only N commits from that branch.
|
|
We reduced the size by around 75% and reduced the number of objects by 98%. The drawbacks of this are we lose history of the repository, git log would only show the latest commit on the repository.
To benchmark, if we try to checkout the branch, we’ll be immediately hit with error: pathspec 'demo-add-training-url' did not match any file(s) known to git error. This is because we only cloned the top commit. Therefore, we’ll need to fetch the branch before we checkout.
|
|
Funny! Checking out a branch took more time than the original clone of the entire repository2. This is the biggest drawback of using a shallow clone. i.e. whenever you want to move from the commit you cloned to any other commit, it often requires downloading a lot of objects. If you’re keeping count this is 34.9x slower.
Partial clone Link to heading
Partial clone is a feature introduced in git 2.29.0 and improved in versions onward. It allows you to fetch only certain objects during the clone and adds promisory notes for the missing objects. Whenever you perform git operation which requires the missing objects, it uses the information in the promisory notes to fetch those objects. This includes operations like git blame, git log etc. Anytime an object is required, git would fetch those objects.
Comparison to shallow clone Link to heading
Partial clone is different from shallow clone we discussed earlier as in shallow clone git would treat the repository as having a single commit, and it wouldn’t auto-magically fetch objects as needed (e.g. if you want to checkout a commit beyond the cloned depth). There is no concept of promisory notes in shallow clone.
Whereas in partial clone, git keeps information about the missing objects in promisory notes, but not the entire object itself. This reduces space on disk but provides flexibility wherein users can always fetch the objects dynamically.
Types of partial clone Link to heading
Partial cloning is done by using the --filter=<filter-spec> flag on git clone. The types of filter spec can be noted in the git-rev-list(1) manual page. Lets discuss two important types of filter-spec:
Filter out blobs Link to heading
We can filter out blobs either with --filter=blob:none or --filter=blob:limit=<n>[kmg]. The former will not fetch any blobs, while the latter will only fetch blobs below the provided size.
|
|
Notice there are two fetch cycles in the git clone, the first is the regular clone without the blobs, which fetched 3578689 objects.
But then since the commit we’d be on points to a tree which would point to certain blobs (directly/indirectly), those blobs got downloaded dynamically by git by looking at the promisory notes. This time we ended up fetching 63071 new objects.
Overall we have reduced our disk space by 48% and the number of objects by 22%.
|
|
On the benchmark side, we can see that this is only 2.5x slower than the baseline. This is because we already have all the required commits/trees and only needed to fetch missing blobs.
Filter out trees Link to heading
We can filter out trees using the --filter=tree:<depth>, where depth refers to how many trees from the root would be downloaded, 0 indicates that no trees would be downloaded.
|
|
Similar to the blob filter, here we see git running multiple fetch cycles after the initial fetch to ensure that the repository is in a usable state. Overall the tree filter is somewhat similar to the shallow clone, wherein we retain only the trees/blobs of the latest commit. But it differs from it by containing all the objects for all commits of the repository and utilizing promisory notes for dynamically obtaining missing objects
Overall we have reduced our disk space by 69% and the number of objects by 89%.
|
|
This is only 2.93x slower than the baseline.
Other filter types Link to heading
There are also other filter types such as --filter=object:type=(tag|commit|tree|blob), in this filter, filtering by commit would be similar to using --filter=tree:0, which we discussed above. Filtering by tree, blob wouldn’t provide much improvements since we’d still download a lot of objects. Finally filtering by tag would be similar to commit, only that we’d have lesser objects (ratio of commits:tags is much lesser than commits:blobs or commits:trees) so it shouldn’t make too much difference.
Conclusion Link to heading
Generally I suggest using the --filter=tree:0 flag while cloning as it provides the best savings on disk space while still providing sufficient performance on regular git tasks. But it all depends on your use case at the end. For e.g. if you’re cloning a repository to only build a binary, you don’t care about git history or objects, in that scenario, a shallow clone is the best option.
Overall the table below should give you some guidance on what to use when:
| Cloning Type | Disk Space | No of Objects | Time to Clone | Checkout Old Branch |
|---|---|---|---|---|
| Regular clone | 2.5G | 4676537 | 191.75s | 6.57s |
| Shallow clone | 0.6G | 76618 | 18.09s | 236.41s |
| Partial clone: no blobs | 1.3G | 3641760 | 90.7s | 16.60s |
| Partial clone: no trees | 0.7G | 511132 | 39.01s | 19.30s |
Footnote Link to heading
1 The objects are often packed into packfiles. This optimization not only allows compression of objects but also storing of objects as deltas over the other objects. The downside is that object lookup now requires not only decompression but for deltas we need to resolve the objects that the delta is based upon (which could be a list of lookups).
2 The time taken being larger than regular clone could be due to a number of reasons. It could be because the server was more busy during that particular fetch hence taking more time for creating the required packfiles. It could be because the server catches packfiles and we requested something totally different.