Code: https://github.com/KarthikNayak/DeepRock
I joined Recurse Center with a goal of learning more about deep-learning. One of the projects I wanted to work on was:
Given a sequence of musical notes (X), can you train a Deep Neural Network to learn improvisation over those notes and come up with its own music (Y).
This post is a step in that direction. First we shall take it one level easier and try to train a model which can learn the intricacies of a Lead guitar and is able to Generate its own composition from the training received.
Obtaining the data Link to heading
We shall use this dataset of midi files as our source for this training.
What is MIDI? Link to heading
MIDI is short for Musical Instrument Digital Interface. Lets think of it as a way to store instrument data, wherein we can think of each song as something which contains one or more instruments (AKA tracks). Each track is said to contain one or more musical notes. Each note is an aggregation of:
- Pitch of the note
- Volume of the note
- Time step relative to previous note
MIDI also contains a lot more data and also metadata related to the said data. But we don’t really care about all that for now.
Parsing the data Link to heading
An important step of all Deep learning projects is ensuring that we parse the data and have good clean data for the model to learn on.
So our plan here is to:
- Filter out only those MIDI files which have a ‘Guitar Instrument’ in them.
- Get all notes form the filtered MIDI tracks for the ‘Guitar Instrument’.
- Split these notes into batches of length
sequence_length + 1. - Only pick sequences which have a minimum of
unique_factornumber of unique notes in them. - Now our
Xwill bedata[0:sequence_length]andYwill bedata[sequence_length] - One hot encode
Y. Normalize and StandardizeX.
Code for the same:
|
|
Model Architecture Link to heading
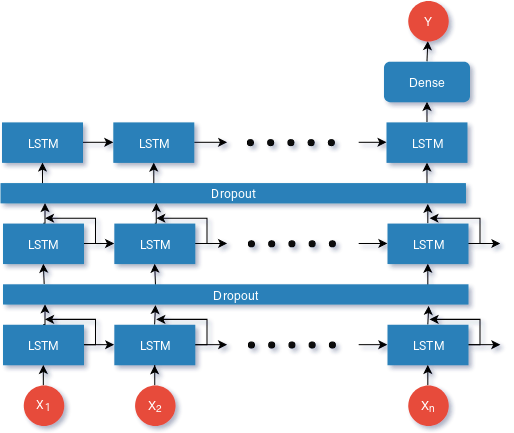
This the model we’ll be using. Some notes here:
- We’ll be using the
Adamoptimizer - Loss will be calculated with
Categorical Cross Entropy. This is because ourYvalues are One-hot Encoded. - We will iterate this training over
learning ratesof 0.01, 0.001 and 0.0001. - We run 200
epochsfor each given learning rate.
Code for the same:
|
|
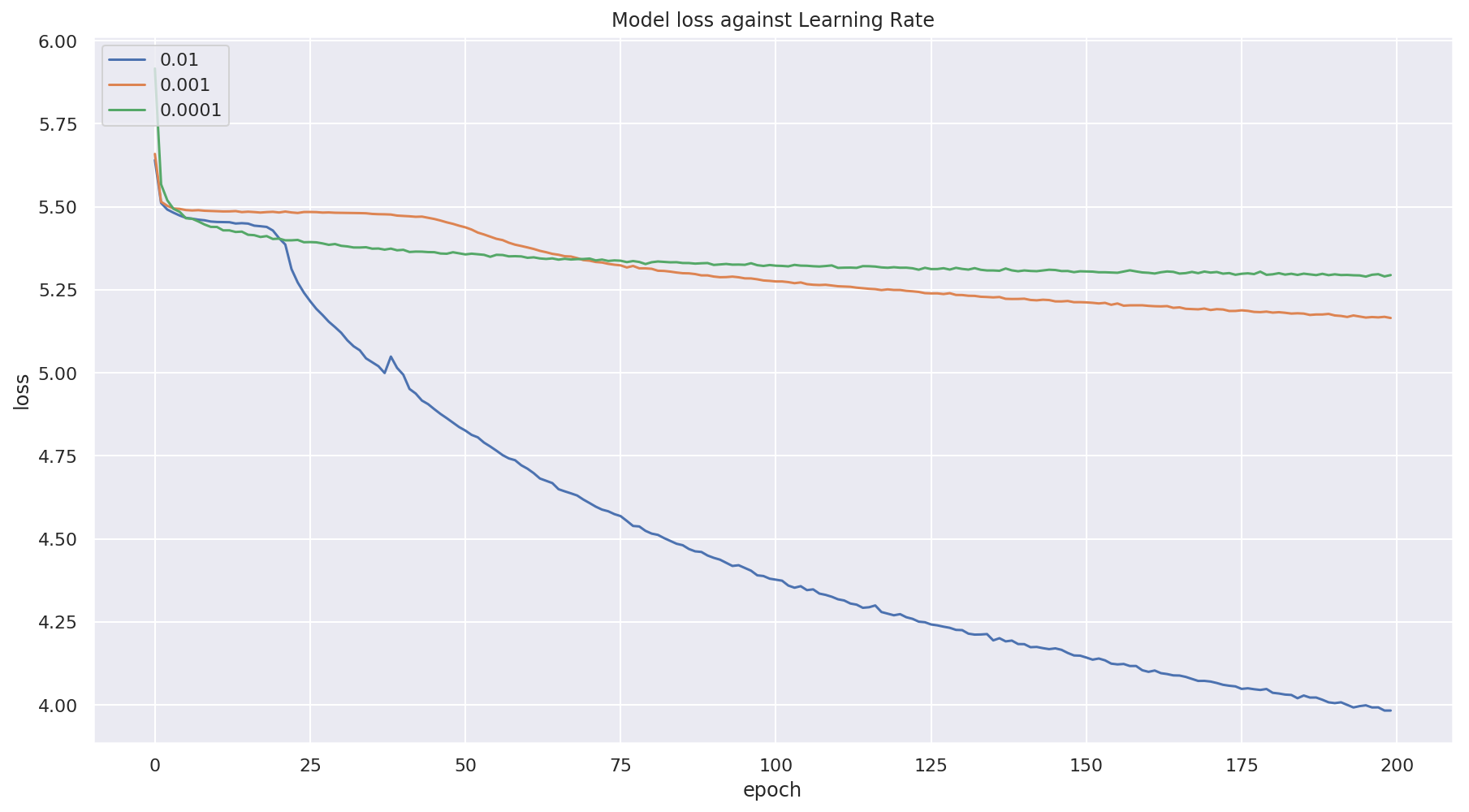
Results Link to heading
The loss against various learning rates are shown below
Music Generation Link to heading
Once the model is trained, generating it is simple.
- We take notes of
sequence_lengthas seed. - We use the seed notes for generating
Y. - We now set the new seed as
prevNotes[1:sequence_length] + Y. - Repeat
Enough talk, wheres the music at?
Note: Music generated above contains the seed given to the generator too.
Key Takeaways Link to heading
Data Cleanup and Parsing Link to heading
When I started off with this project, my expectation was to finish the project within 1 week. I undershot by a mile. It took exactly two weeks to actually wrap it up. This is mostly because I didn’t expect so much clean up would be required for the data I had gotten.
I’ve come to realize that with any Deep learning project, A good amount of time is spent in the data collection and aggregation stage. This is due to one of the following reasons
- Data tends to be inconsistent in many forms. Here although the data set was huge, most of it was junk. This is because the dataset was mostly a collection of user submitted MIDIs which didn’t adhere to any quality control.
- Data can be missing. Some MIDI files, didn’t contain metadata of which track belonged to which instrument. I even tried writing some logic to parse these tracks and do a probabilistic guess as to which track could be for the guitar. Although this worked on my small test set. I couldn’t scale if efficiently
- Data can be repeated. Although this is minimal, I’ve noticed that parts of the data is repeated. This again is of two types WRT our context
- Multiple versions of a songs MIDI. This is because multiple users have submitted a MIDI for the same file. This means we have repeated information for some songs. We’ve ignored this constraint.
- Songs can have repeated notes. This is especially true in Rock music, where the guitar could repeat a sequence of notes over the song. We try to eliminate this using the
unique_factorvariable.
Hyper-Parameter Modification Link to heading
I always overlooked this whenever I’ve gone through tutorials for deep-learning. But I cannot stress on how important this is. Hyper-Parameter tuning is really really important.
Having the right Hyper-Parameters can be deciding factor between a successful model and a model that doesn’t work at all.
I was stuck for a day with a model which was predicting the same output irrespective of the data being fed to the model. I couldn’t figure out why this was happening, as a last resort I tried to change the learning rate. This simple change got me a working model. Surprising.